CLI 命令行工具
千帆 SDK 提供了 CLI 工具,方便在命令行中直接使用千帆平台各项功能。
使用方法:
使用前需要配置鉴权相关信息,关于 Access Key 和 Secret Key 的获取方式参考 文档。除了使用环境变量,也可以通过下方命令行参数传递,或者是通过当前文件夹的 .env 文件 配置。
$ export QIANFAN_ACCESS_KEY=your-access-key
$ export QIANFAN_SECRET_KEY=your-secret-key
$
$ qianfan [OPTIONS] COMMAND [ARGS]...
基础参数:
IMPORTANT:以下参数必须位于 command 命令之前,否则会被识别成命令的参数而无法生效。
--access-key TEXT:百度智能云安全认证 Access Key,获取方式参考 文档。--secret-key TEXT:百度智能云安全认证 Secret Key,获取方式参考 文档。--ak TEXT[过时]:千帆平台应用的 API Key,仅能用于模型推理部分 API,获取方式参考 文档。--sk TEXT[过时]:千帆平台应用的 Secret Key,仅能用于模型推理部分 API,获取方式参考 文档。--enable-traceback:打印完整的错误堆栈信息,仅在发生异常时有效。--version -v:打印版本信息。--install-shell-autocomplete:为当前 shell 安装自动补全脚本。--show-shell-autocomplete:展示自动补全脚本。--help -h:打印帮助文档。
命令:
chat对话completion补全txt2img文生图dataset数据集
chat 对话
用法:
$ qianfan chat [OPTIONS]
Options 选项:
--model TEXT:模型名称 [default:ERNIE-Bot-turbo]--endpoint TEXT:模型的 endpoint--multi-line / --no-multi-line:多行模式,提交时需要先按下 Esc 再回车,以避免与文本换行冲突 [default:no-multi-line]--list-model -l:打印支持的模型名称列表--help:展示帮助文档
completion 补全
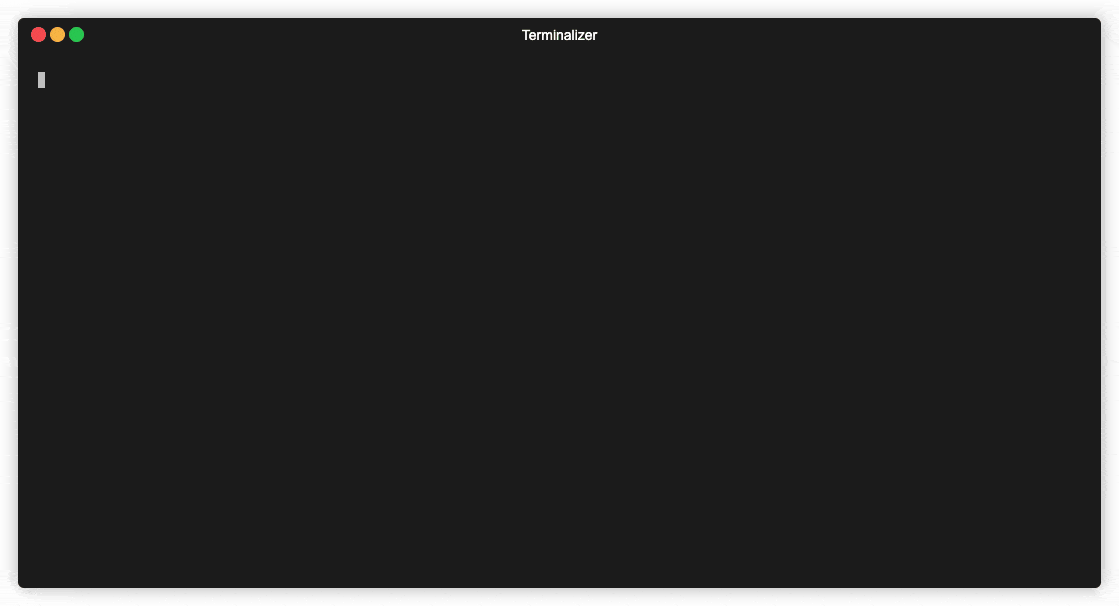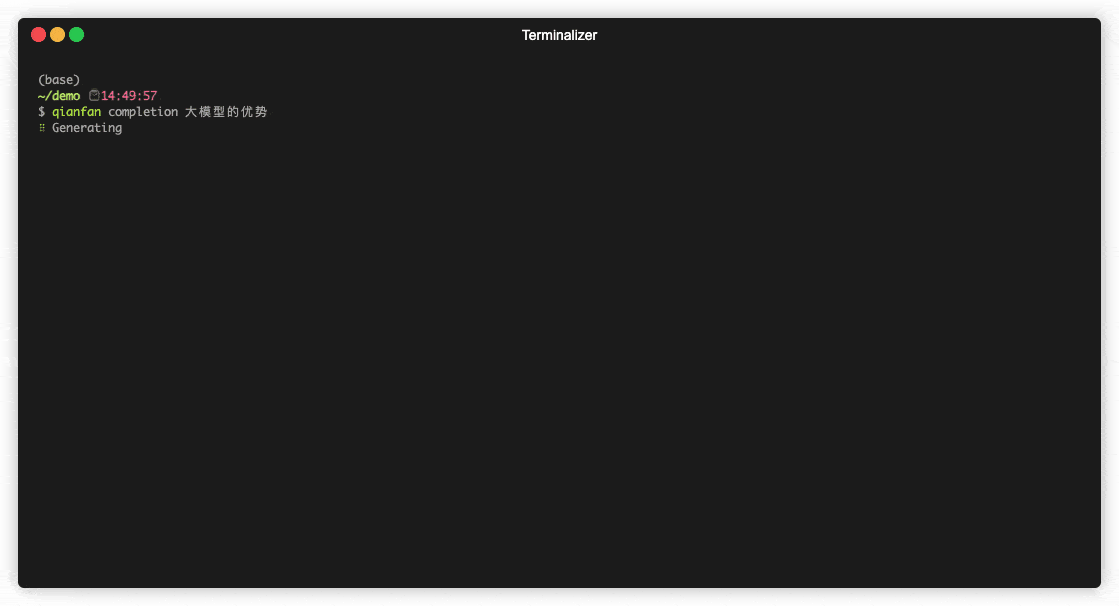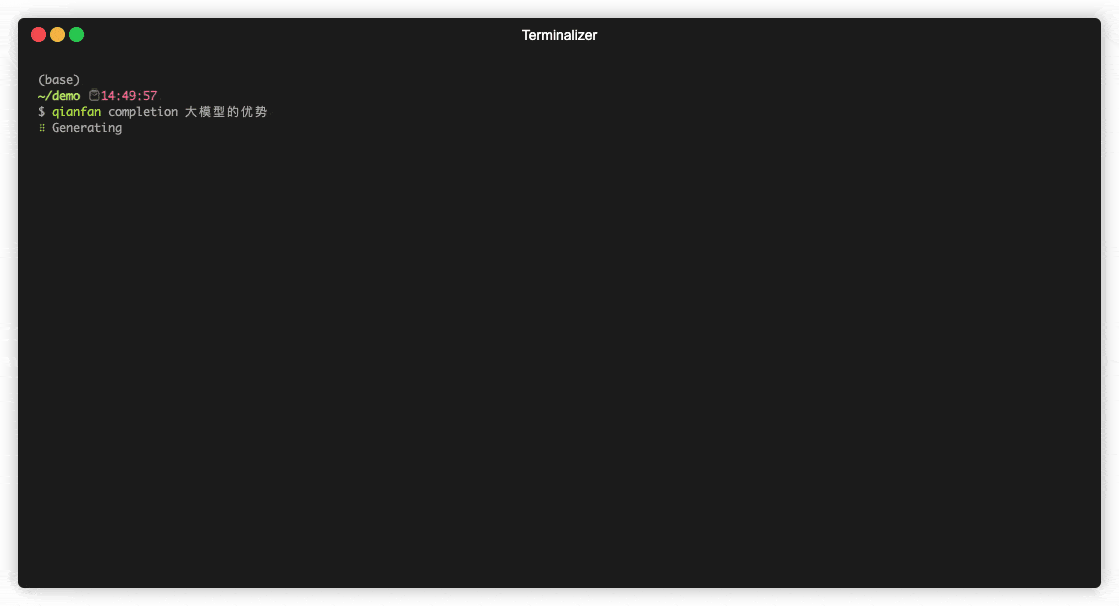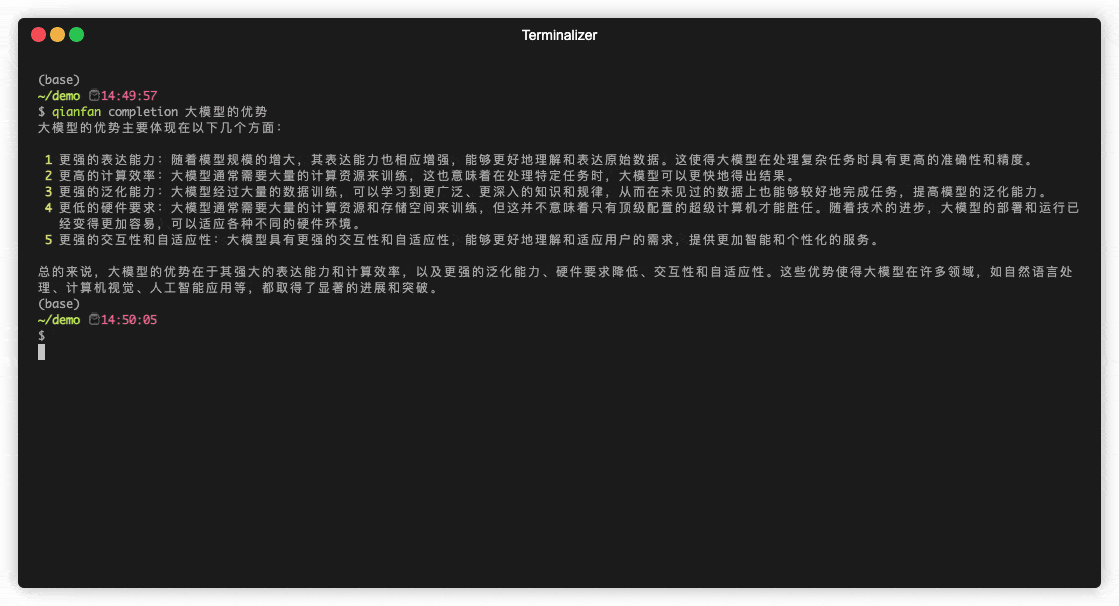
用法:
$ qianfan completion [OPTIONS] PROMPTS...
Arguments 参数:
PROMPTS...:需要补全的 prompt,支持传递多个 prompt 以表示对话历史,依次表示用户和模型的消息,必须为奇数。如不传递则需要在命令行中交互输入。
Options 选项:
--model TEXT:模型名称 [default:ERNIE-Bot-turbo]--endpoint TEXT:模型的 endpoint--plain / --no-plain:普通文本模式,不使用富文本 [default:no-plain]--list-model -l:打印支持的模型名称列表--multi-line:多行模式,提交时需要先按下 Esc 再回车,以避免与文本换行冲突--help:展示帮助文档
txt2img 文生图
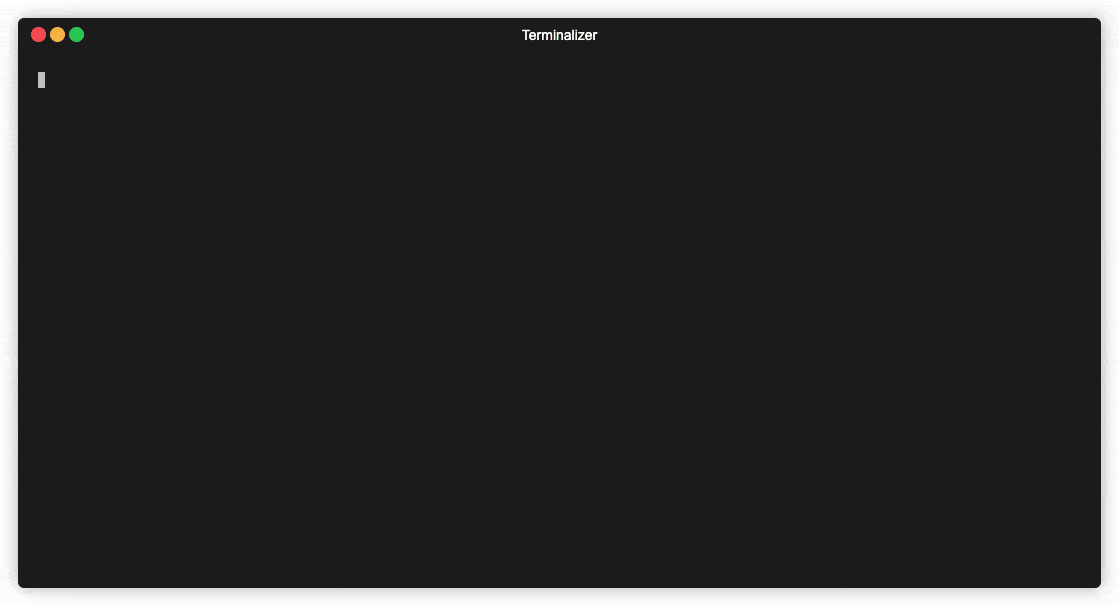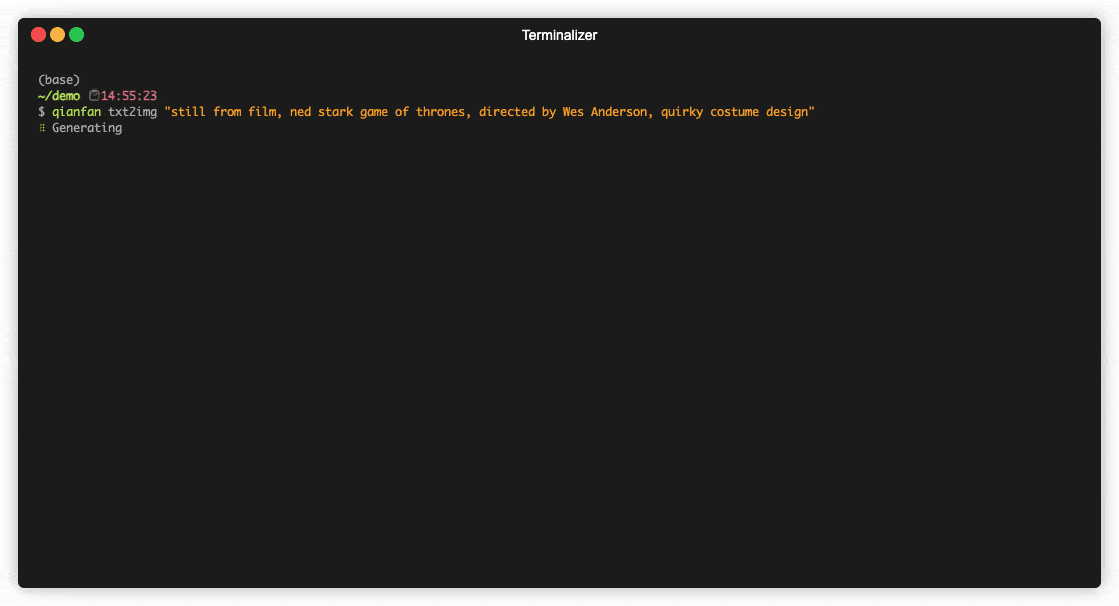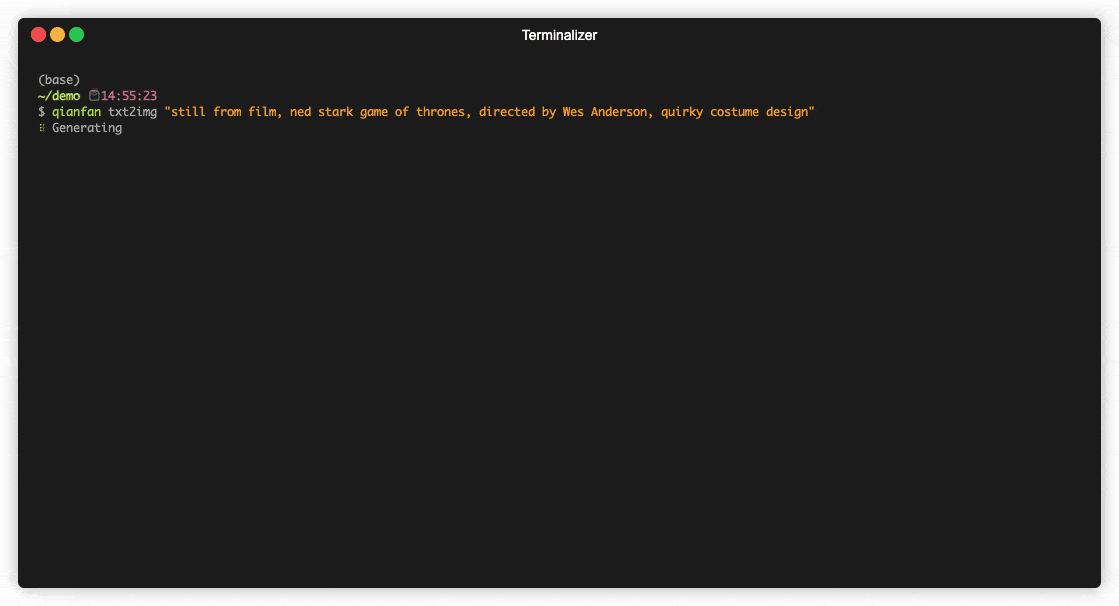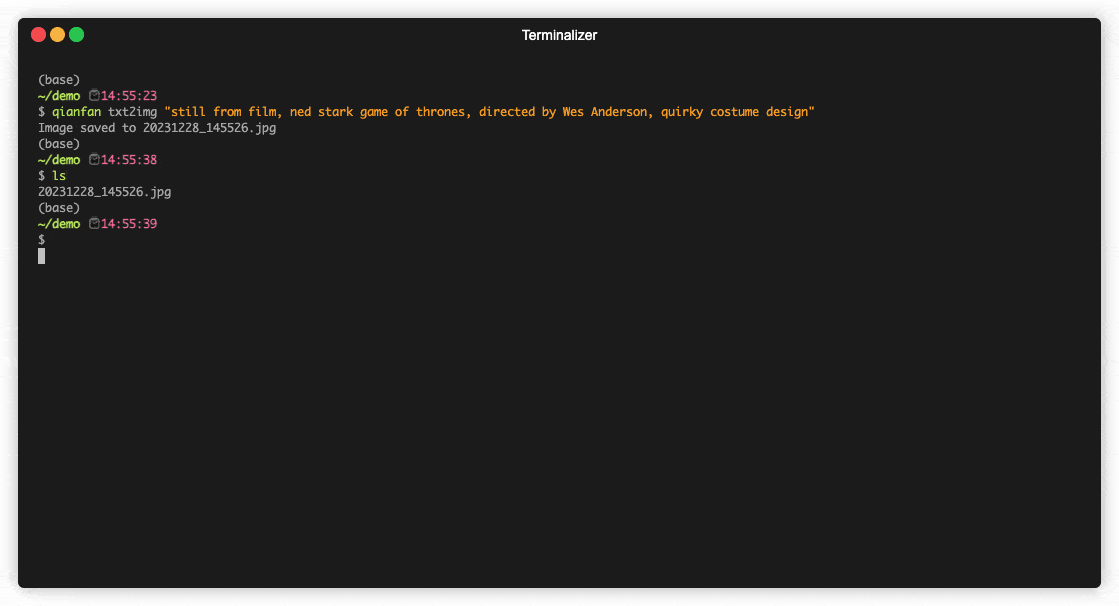
用法:
$ qianfan txt2img [OPTIONS] PROMPT
该命令依赖 Pillow,需要使用该功能的话可以通过 pip install Pillow 安装,具体参考 Pillow 安装文档。
Arguments 参数:
PROMPT:生成图片的 prompt [required]
Options 选项:
--negative-prompt TEXT:生成图片的负向 prompt--model TEXT:使用的模型名称 [default:Stable-Diffusion-XL]--endpoint TEXT:使用的模型 endpoint--output PATH:输出的文件名称 [default:%Y%m%d_%H%M%S.jpg]--plain / --no-plain:普通文本模式,不使用富文本 [default:no-plain]--list-model -l:打印支持的模型名称列表--help:展示帮助文档
dataset 数据集
用法:
$ qianfan dataset [OPTIONS] COMMAND [ARGS]...
Options 选项:
--help:展示帮助文档
Commands 命令:
predict:调用大模型对数据集进行预测,并保存到本地文件。download:下载数据集。upload:上传数据集。save:保存数据集至本地文件或平台。view:预览数据集内容。
⚠️ 在下方各个数据集的命令中,涉及数据集 id 均指平台上的数据集版本 id,与 Dataset 模块定义一致,具体获取方式参考 文档。
使用时可以直接传数据集的 id,也可以使用链接形式避免与文件名产生歧义,格式为
qianfan://{dataset_version_id},例如qianfan://18562。如果由于本地文件名为数字,导致和数据集 id 混淆,可以在文件名前增加
./避免歧义,例如./18562。
predict 数据集预测
调用大模型对数据集进行预测,并保存到本地文件。
用法:
$ qianfan dataset predict [OPTIONS] DATASET
Arguments 参数:
DATASET:待预测的数据集。值可以是一个本地文件的路径,也可以是平台上的数据集链接 (格式为qianfan://{dataset_version_id})。 [required]
Options 选项:
--model TEXT:预测用的模型名称,可以用qianfan chat --list-model获取模型列表。 [default:ERNIE-Bot-turbo]--endpoint TEXT:预测用的模型 endpoint,该选项会覆盖--model选项。--output PATH:输出的文件路径。 [default:%Y%m%d_%H%M%S.jsonl]--input-columns TEXT:输入的列名称。 [default:prompt]--reference-column TEXT:参考答案的列名称。--help:展示帮助文档。
download 数据集下载
下载数据集至本地。

用法:
$ qianfan dataset download [OPTIONS] DATASET_ID
Arguments 参数:
DATASET_ID:待下载的数据集版本 id。 [required]
Options 选项:
--output TEXT:输出的文件名称 [default:%Y%m%d_%H%M%S.jpg]--help:展示帮助文档。
upload 数据集上传
上传本地数据集文件至平台。
用法:
$ qianfan dataset upload [OPTIONS] PATH [DST]
Arguments 参数:
SRC:数据集文件路径。 [required][DST]:目标数据集 id,该参数可选。如果不提供该值,那么将会在平台上创建一个新的数据集,否则数据将被追加至所提供的数据集中。值可以是数据集的 id 或者是千帆数据集链接 (qianfan://{dataset_version_id})。
Options 选项:
--dataset-name TEXT:新建数据集的名称,仅在不提供DST参数时需要。--dataset-template-type [non_sorted_conversation|sorted_conversation|generic_text|query_set|text2_image]:数据集的类型,仅在不提供DST参数时需要。 [default:non_sorted_conversation]--dataset-storage-type [public_bos|private_bos]:数据集存储的类型,仅在不提供DST参数时需要。 [default:private_bos]--bos-path TEXT:数据集保存在 BOS 上的路径。 (e.g. bos://bucket/path/) [required]--help:展示帮助文档。
save 数据集保存
保存数据集至本地文件或平台。
upload和download命令提供了更为方便的上传和下载数据集的方法,满足需求的前提下建议优先使用这两个命令。
save命令提供了更为灵活的数据集保存功能,例如平台数据拷贝至另一个平台数据集中,可以满足更为复杂的需求。
用法:
$ qianfan dataset save [OPTIONS] SRC [DST]
Arguments 参数:
SRC:源数据集。值可以是一个本地文件的路径,也可以是平台上的数据集链接 (格式为qianfan://{dataset_version_id})。 [required][DST]:目标数据集。如果值是一个本地文件路径,那么数据将保存至该文件中。或者可以提供一个已有的千帆数据集链接 (qianfan://{dataset_version_id}),那么数据将被追加至该数据集中。如果不提供该值,那么将会在平台上创建一个新的数据集,此时需要提供创建数据集所需的一些参数,具体见下文。
Options 选项:
--dataset-name TEXT:新建数据集的名称,仅在不提供DST参数时需要。--dataset-template-type [non_sorted_conversation|sorted_conversation|generic_text|query_set|text2_image]:数据集的类型,仅在不提供DST参数时需要。 [default:non_sorted_conversation]--dataset-storage-type [public_bos|private_bos]:数据集存储的类型,仅在不提供DST参数时需要。 [default:private_bos]--bos-path TEXT:数据集保存在 BOS 上的路径,仅在保存至平台时需要。 (e.g. bos://bucket/path/)--help:展示帮助文档。
view 数据集预览
预览数据集内容。
用法:
$ qianfan dataset view [OPTIONS] DATASET
Arguments 参数:
DATASET:待预览的数据集。值可以是一个本地文件的路径,也可以是平台上的数据集链接 (格式为qianfan://{dataset_version_id})。[required]
Options 参数:
--row TEXT:待预览的数据集行。用,分隔数个行,用-表示一个范围 (e.g. 1,3-5,12)。默认情况下仅打印前 5 行,可以通过--row all来打印所有数据。--column TEXT:待预览的数据集的列。用,分隔每个列名称。 (e.g. prompt,response)--raw:展示原始数据。--help:展示帮助文档。
trainer 训练
用法:
$ qianfan trainer [OPTIONS] COMMAND [ARGS]...
Options 选项:
--help:展示帮助文档
Commands 命令:
run:运行 trainer 任务
run
运行 trainer 任务
用法:
$ qianfan trainer run [OPTIONS]
Options 选项:
--train-type TEXT:训练类型 [required]--dataset-id INTEGER:数据集 id [required]--help:展示帮助文档
训练相关配置,参数含义与 训练 API 文档 中对应参数含义一致:
--train-epoch INTEGER:训练轮数--train-batch-size INTEGER:训练每轮 batch 的大小--train-learning-rate FLOAT:学习率--train-max-seq-len INTEGER:最大训练长度--train-peft-type [all|p_tuning|lo_ra]:Parameter efficient finetuning 方式--trainset-rate INTEGER:数据拆分比例 [default:20]--train-logging-steps INTEGER:日志记录间隔--train-warmup-ratio FLOAT:预热比例--train-weight-decay FLOAT:正则化系数--train-lora-rank INTEGER:LoRA 策略中的秩--train-lora-all-linear TEXT:LoRA 是否所有均为线性层
部署相关配置,参数含义与 创建服务 API 文档 中对应参数含义一致:
--deploy-name TEXT:部署服务名称。设置该值后会开始部署 action。--deploy-endpoint-prefix TEXT:部署服务的 endpoint 前缀--deploy-description TEXT:服务描述--deploy-replicas INTEGER:副本数 [default:1]--deploy-pool-type [public_resource|private_resource]:资源池类型 [default:private_resource]--deploy-service-type [chat|completion|embedding|text2_image]:服务类型 [default:chat]